Be explicit about a class's multiple interfaces
I’ve been working on The Server Framework this week. A client wanted a version of the latest framework with UDP support added. They’d taken the freely available version of the code a couple of years ago and I’d given them some hints as to how they could get it to deal with UDP. This worked well for them and they’ve built a rather large VOIP system on top and now they’re having some performance problems. My first suggestion to them was to add some performance counters so that we could see what was going on. They decided that they liked that idea and that they also wanted to pay for me to develop a UDP version of the code using our latest framework. I guess once they’re using that, the performance problems become my problem ;).
A couple of years ago I’d hacked together a UDP server using the framework but it was a nasty cut’n’paste’n’hack thing and as we didn’t have any clients for the code the required refactoring never got done. This time, with the prospect of having to maintain and enhance the code for our clients, I decided to do the work properly.
When I refactored the main parts of The Server Framework early last year, so that I could test it more easily, I broke the core monster server object into four pieces but I didn’t have the time (or energy) to do the same with the socket object. To add a UDP server to the mix means sharing some, but not all, of the TCP socket code and to do that without duplication meant that I needed to face breaking the CAsyncSocket object up into its component parts. However, that wasn’t where I started. I started by taking a similar approach to the first time that I did the work; I hacked a UDP version together quite quickly using cut’n’paste’n’hack techniques.
I find it easier to remove duplication when the duplication exists. Sure, I could have sat down with a pile of paper and scribbled out a design for how the UDP server would share code with the TCP server but that design wouldn’t actually be tested until I’d done the work and written the code. What’s more, since the code that I would be changing doesn’t have full test coverage I would be working on untestable code and potentially breaking existing functionality… Instead I used the old design as a template and created a new version based on the new framework code. This left me with LOTS of duplication but it worked. Once I had something that worked I created a set of test servers to demonstrate it working and put together some black box tests that thrashed the servers and proved that they worked. Now I had tests. Admittedly these tests were at a very high level; have ‘x’ 100 clients push ‘y’ 1000 bytes through the server and make sure that the server echoes the bytes back in a correct and timely fashion… But the thing is these tests are better than no tests. Once the tests were in place I could start work on refactoring the UDP code with the eventual aim of removing all the duplication and ending up with a unified framework that can handle both UDP and TCP. As the refactoring progressed it became easier to add proper localised unit tests.
The first thing that I decided to look into was the size of the socket object. It’s a complex beast that’s reference counted and passed around by pointer. The existing code had lots of friend relationships with other classes. These were present because the socket object had a public and a private interface, the clients of the framework used the public interface and the server code used the private interface; unfortunately the distinction between interfaces was simply that the public interface consisted of publicly accessible functions and the private interface worked by letting some other classes access private functions in the socket object… Can you smell what it is yet? ;) The friendship thing had proven to be an obstacle to extensibility in the past; adding a new server type meant that you had to alter the socket (by adding a friend)… We clearly violated the Open/Closed principle. The design didn’t start out quite this bad but it had grown that way over time.
Solving this kind of problem is relatively straight forward but it requires change and I hadn’t been prepared to make the kind of wide ranging changes before. The first thing I did was go through the functions that the socket object provided and find out who used them. When you do something like this you usually end up with sets of functions grouped together by the code that uses them. The socket class actually had three distinct interfaces: Firstly there’s the client interface, this is the interface that users of the framework use. Next comes the server interface, this is used internally by the framework so that the socket server, or connection manager object can manage the sockets. Finally there’s the socket pooling interface, to minimise memory allocations we can keep sockets hanging around after they’re finished with and use them on subsequent connections. Creating real abstract base class interfaces from these collections of related functions was pretty easy; teasing the code apart so that each distinct area only worked with the appropriate interface was less so.
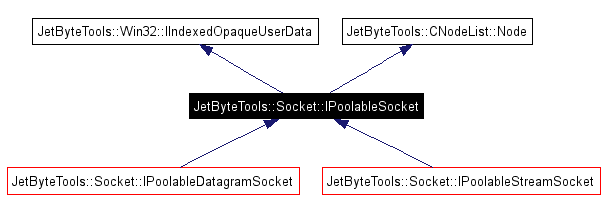
IPoolableSocket
The ‘poolability’ of the socket is orthogonal to the rest of the things a socket does. Neither the server nor the clients of the framework should need to know, or care, that the socket they’re using can be pooled; in fact, it’s better that they don’t know as it stops them messing with things they’ve no need to mess with. This also means that the socket allocator can be written in terms of an IPoolableSocket interface. By breaking apart the functionality so that the user of the functionality only needs to see the functionality that it uses, rather than all of the object’s functionality, we make the code easier to understand. Since both TCP and UDP sockets can be pooled in the same way we can share the code. A thin template around the non-template socket allocator can provide for the creation of the correct socket type and for type-safe conversion from IPoolableSocket to our connection specific poolable socket interface.
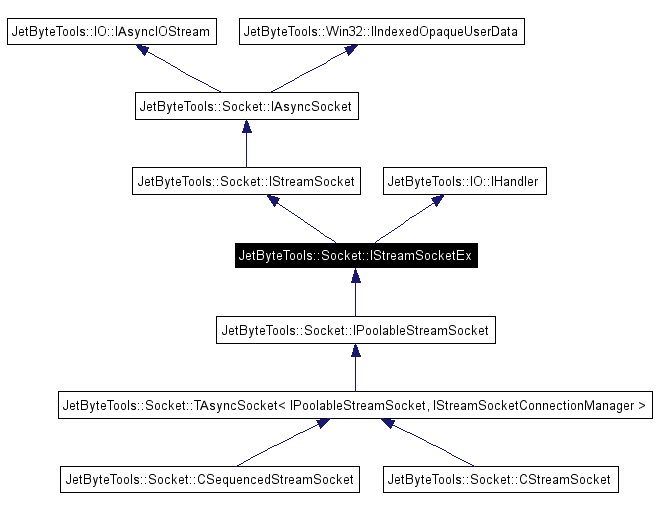
IStreamSocketEx
The server interface and the client interface are more closely related. The client interface contains just the functions that a client of the framework should use to manipulate a socket connection. The server interface contains the additional functions that are used to manage the connection. As you can see from the, rather complex, diagram above IStreamSocketEx, the server interface, derives from IStreamSocket, the client interface. Wherever we are manipulating a socket object inside the server we can always pass it out to a client and the client will only use the smaller, more targeted, interface. The IAsyncSocket interface is one point in the design where TCP and UDP sockets share functionality. If you don’t care about the TCPness of a connection you can work in terms of IAsyncSocket and be quite at home if you’re given a UDP socket instead… The lowest level of the inheritance hierarchy is IAsyncIOStream which was born during my test driven POP3 development. This interface was my first attempt at breaking the link between code that uses these sockets and the socket itself. This interface isn’t at all sockety, it just does IO in an async way (note that read doesn’t return anything…)
class IAsyncIOStream
{
public :
virtual void Read() = 0;
virtual void Read(
IBuffer *pBuffer) = 0;
virtual void Write(
const char *pData,
size_t dataLength) = 0;
virtual void Write(
const BYTE *pData,
size_t dataLength) = 0;
virtual void Write(
IBuffer *pBuffer) = 0;
protected :
virtual ~IAsyncIOStream() {}
};
It’s all that the bulk of the POP3 code, or, to be honest, most server code, needs to deal with. It’s small, compact and easy to mock up…
Back with the server interface you’ll notice that it also inherits from the IHandler interface. This is the interface that is used with our IO Completion port class. A handler is our “completion key”. When we do async IO via an IOCP we pass the socket as an instance of IHandler and the IOCP wrapper knows how to dispatch the call to the handler… The client of The Server Framework need not, and should not, know or care that we’re using IOCP or that the socket they’re given is also an IHandler and this design means that they never do…
Above IStreamSocketEx we have a templatised implementation of most of the shared functionality that TCP and UDP sockets share at the IAsyncSocket level, with the TAsyncSocket<> template. This is where all of the code that is common between TCP and UDP lives. By the time I got the design to this point it was relatively obvious which code was shared and which was not. The shared code was moved across into the template so that it could be used for all socket types.
The datagram interface hierarchy looks something like this:
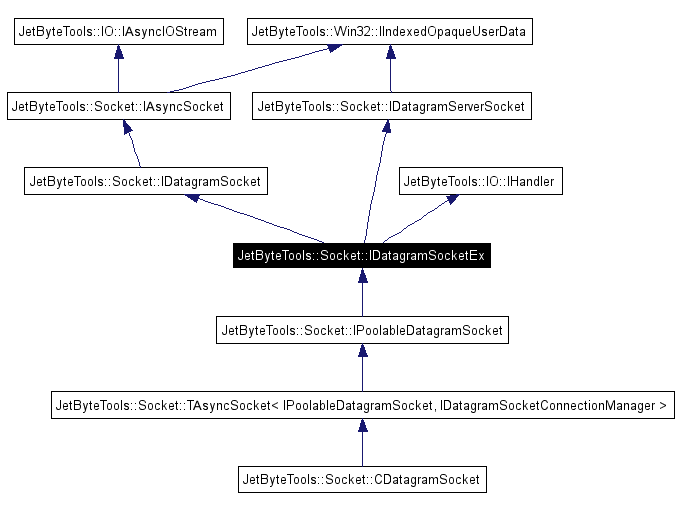
IDatagramSocketEx
Unfortunately Doxygen didn’t draw this quite as neatly as the stream socket version… This is mainly because we currently have two different clients for the datagram socket. The datagram socket interface that’s used for datagram “servers” has a very restricted interface, all you can do is reply to the datagram that you received. The interface that’s used by the datagram connection manager, which can initiate outbound connections, is more fully featured and allows you to RecvFrom and SendTo whoever you want, as well as supporting the pseudo “connected” mode that the server socket supports… As you can see the whole point of these interface is simply to restrict what the user of the object can do with the object when they’re given it; hence the distinction between a datagram socket that’s used for initiating outbound connections and one that’s used as part of a server… By restricting what a client can do with an interface by making it as narrow as possible you remove complexity and confusion and ensure that the client can only perform the actions that it’s supposed to be able to perform… The less it can do the less you need to understand to make changes to it and the less that you need to test. This seems quite at odds with the ideas coming from the dynamically typed languages crowd. I personally prefer that even if it looks like a duck it’s only a duck if I say so.
Once everyone deals in interfaces rather than concrete objects you can start getting a little more flexible about how you implement the interfaces. For example, you’ll see from the stream socket diagram above that during the refactoring work I decided to change how sequenced sockets worked by moving the code into its own class CSequencedStreamSocket. Sequenced sockets are sockets where we may have multiple sends or receives in progress at any one time, as such we need to make sure that we deal with any sequencing issues that arise from using IOCP’s and multiple worker threads to process these reads and writes, if the client issues 3 write requests to a socket it likely wants the data to arrive in the order that it sent it and that can be a little more complicated to get right than you’d think - I deal with this issue in more detail here. The thing is, you don’t always need support for this and including support in the way that we currently provide it adds a couple of synchronisation points that aren’t required if you don’t need the support. Because of this sequencing support has always been optional and because I wanted to avoid having an extra pointer stored in the socket class we used to store the extra data required in the socket’s user data and then adjust the user’s access to the user data so that they didn’t need to know that we had hidden some sequencing data in there… This was as much of a hack as it sounds, but it worked and there was no reason to change it, and what’s more it was hard to change because all clients expected an instance of CAsyncSocket not just an implementation of IStreamSocket. Anyway, now that clients are dealing in terms of an interface there’s nothing to stop us having a separate socket class for dealing with sequenced sockets. I used the same cut’n’paste’n’hack technique to create a CSequencedStreamSocket class from the CStreamSocket class and then removed the sequencing code from CStreamSocket and reimplemented it in CSequencedStreamSocket so that it didn’t hijack a user data slot… Once my tests showed that I hadn’t broken anything I removed the duplication by deriving CSequencedStreamSocket from CStreamSocket, after all the sequenced stream socket ISA stream socket with sequencing…
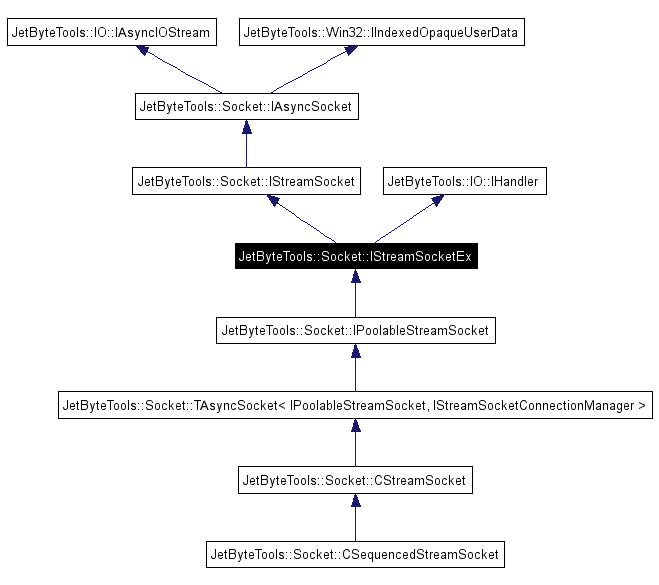
IDatagramSocketEx2
So, what has all of this achieved? We now have support for UDP and TCP within the framework and we have minimal code duplication. Maintaining the code should be easier; we’re not going to be able to update the TCP code without keeping the UDP code in sync. We have many more files than we did before; this means that the code looks more complex, but it’s not. It’s easy to make the mistake of assuming that many files == complex code; it can do, but often many files == code that’s factored into classes that do just one thing. One of the reasons that we have many more files is that we have lots of interfaces. Each of these interfaces represents a potential inflection point in the code. Going forward I should be able to increase the test coverage for the socket framework by creating and working with mock objects that implement or instrument all or part of these interfaces. Clients of the framework are now decoupled from a concrete socket class. If we need some special socket for a particular purpose then we can now simply create the new socket class and a matching socket allocator and simply pass the allocator to anyone who’d usually work with a socket allocator. Many areas of the code are now much more restricted in what they can do with a socket; one particular example is the OnSocketReleased() callback. This callback is called when a socket’s reference count has reached zero and the socket is about to be returned to the pool. It exists so that any dynamic user data that was added to the socket during its lifetime can be cleaned up. Prior to the refactoring we passed a pointer to a CAsyncSocket to this function and we had some special checks within CAsyncSocket::AddRef() to make sure that someone didn’t try and bring the socket back to life. Now we pass an instance of IIndexedOpaqueUserData to this function and there’s no scope for mistakes. All you can do is manipulate the socket’s user data. The special-case checks in CAsyncSocket::AddRef() can come out, making that code easier to understand and the documentation to OnSocketReleased() can be simplified as there’s now no need to say “you’re given a socket but it’s in a weird zombie state and you can only use these few methods on it”. You get an instance of IIndexedOpaqueUserData and you can use any or all of its functionality. And finally, of course, anywhere that I use TCP or UDP above we’re actually talking about stream sockets and datagram sockets of any description.
All in all the new design is more flexible and more testable. I’m looking forward to getting some more tests in place so that I can finally move away from using my OpenSSL echo server black box test as the ‘mother of all tests’ for the framework. Now all I need to do is finish the UDP sample servers and get those tests written.