Performance comparisons for recent code changes
As I mentioned yesterday, I’ve been doing some performance testing using the command line interface to perfmon to record the results. Today I automated the stuff I was playing with over the weekend and ended up with a script that can set up a perf log trace, install a particular build of a service, run a test from a remote client machine (using winrs) and then stop and remove the perf log and the service. Another script then calls the first script and tells it which versions of the code to test. Once all of the code has been tested the logs are loaded up into the database and perfmon is used to inspect the results.
The next step is to write some reporting that can pull out summary information based on the test runs, but for now I’m just looking at the squiggly lines.
This first chart shows the difference between 6.1 and 6.2 with the FILE_SKIP_COMPLETION_PORT_ON_SUCCESS turned off. It’s not a like-for-like comparison as the 6.2 code is built with Visual Studio 2010 and the 6.1 code is built with Visual Studio 2008. However if you allow for the fact that the 6.2 release was the first to include support for VS2010 and that the release also includes some major work to remove the filtering code from servers that don’t need it’s a pretty good performance gain for a simple rebuild.
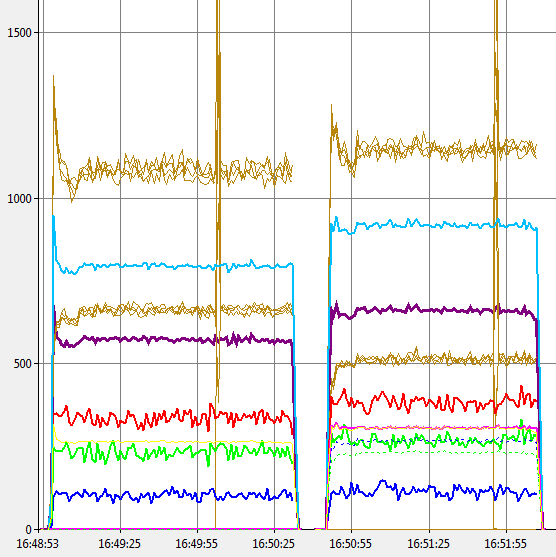
6.1, 6.2 No Skip
The width of the two charts shows the relative time taken for the test (5000 connections sending 500 x 1024 byte messages) to complete. The brown squiggles are thread context switches per second. Red is % processor time (8 cores, so 800 is 100% CPU), Green is kernel time, Dark Blue is user time. The thick purple line is Total Bytes/sec through the network interface. Light blue is I/O pool events per second. All counters are scaled to fit and the scaling and relative widths of the charts remain constant over the next charts…
This next chart shows the 6.2 release. First we have FILE_SKIP_COMPLETION_PORT_ON_SUCCESS turned off, next with it turned on and finally with the experimental changes to remove the marshalling of socket operations to the I/O pool.
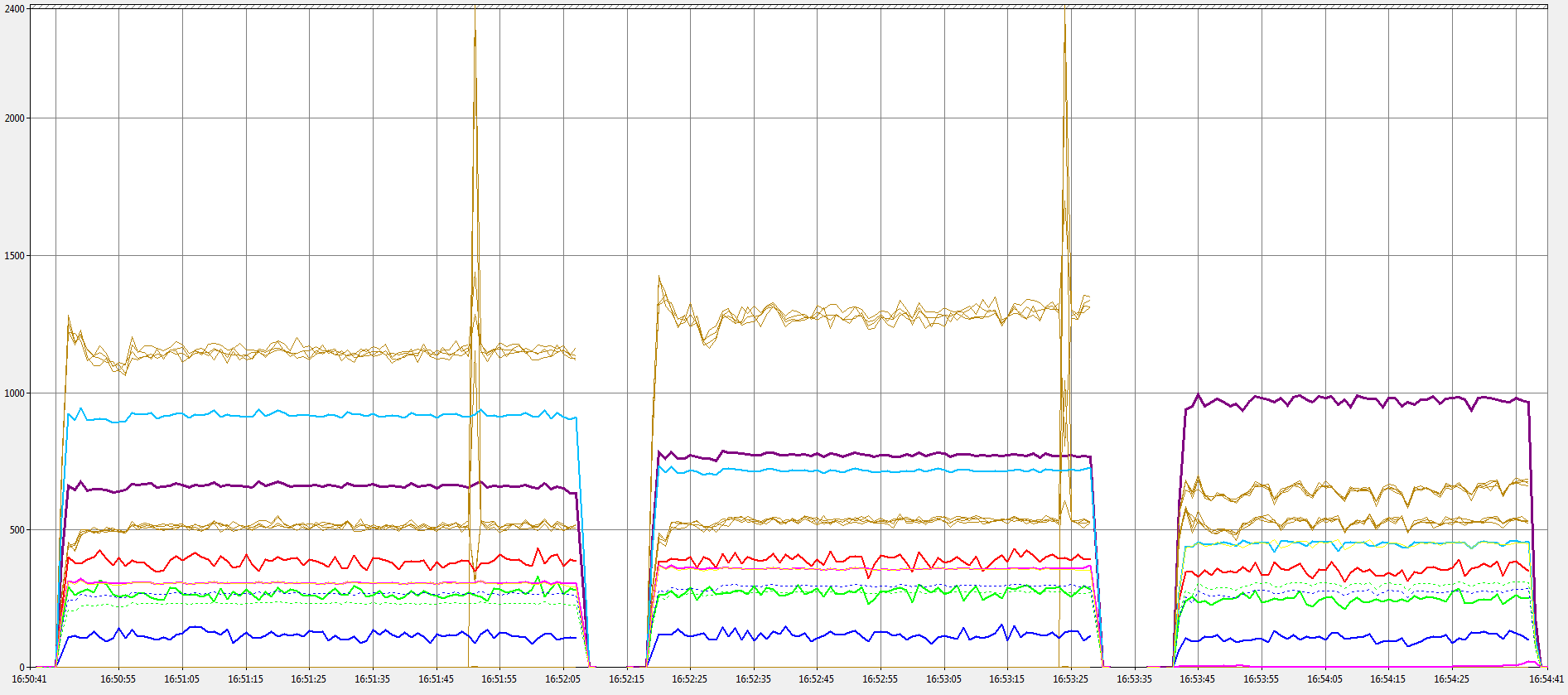
6.2 - No Skip, Skip, No Marshal
This clearly shows the improvements that can be had by enabling these new options. Note how enabling FILE_SKIP_COMPLETION_PORT_ON_SUCCESS reduces the amount of work that the I/O thread pool needs to do (light blue line, I/O pool events/sec, is lower) and how removing the explicit marshalling of I/O requests reduces the I/O events further and spreads the work more evenly across the two thread pools (brown squiggly lines are all much closer rather than in two distinct groups). In the final chart you can also see that the I/O events/sec counter has taken the place of the pink line (I/O events dispatched/sec). The pink line now sits at zero for most of the time as we’re no longer dispatching marshalling events to the I/O pool. Hidden behind the blue line in this last chart (and the pink line in the earlier two charts) is a yellow line which is the number of business logic pool events/sec. As you can see this is higher in the final chart as we’re doing more work quicker. You can also see the dotted dark blue and green lines which show the contention in the buffer allocator.
Next up we have the same server using the lock free buffer allocator.
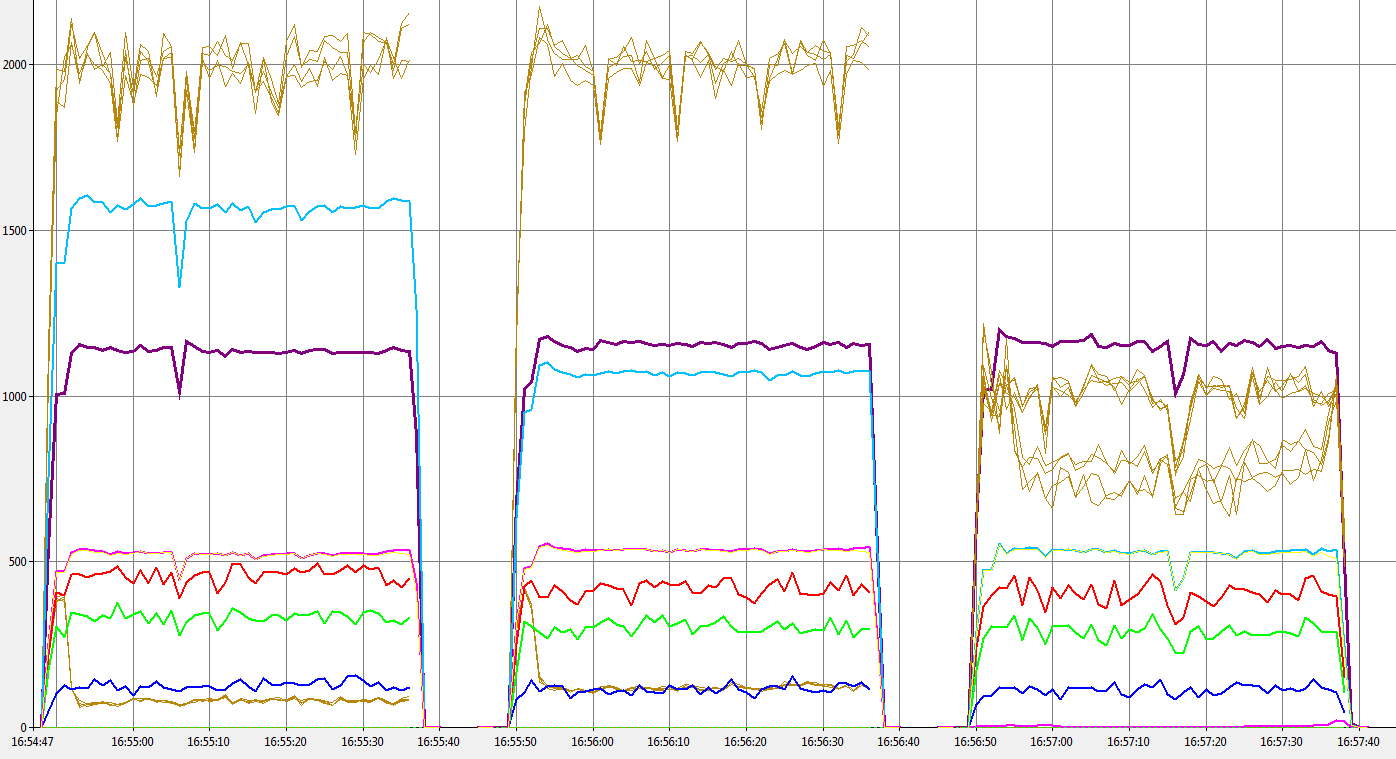
6.2 LockFree - NoSkip, Skip, NoMarshal
The surprising thing for me about these charts is how much better the lock free allocator is than the normal allocator. It’s probably about what you would expect given the contention in the normal allocator but it surprised me since in previous testing the lock free allocator didn’t really make a great deal of difference. Note that whilst these tests don’t benefit so much from the latest changes they go to show that using the lock free allocator can help quite a bit on its own.
Finally we have the low contention allocator. This performs very slightly better than the lock free allocator if tuned correctly (as it is here).
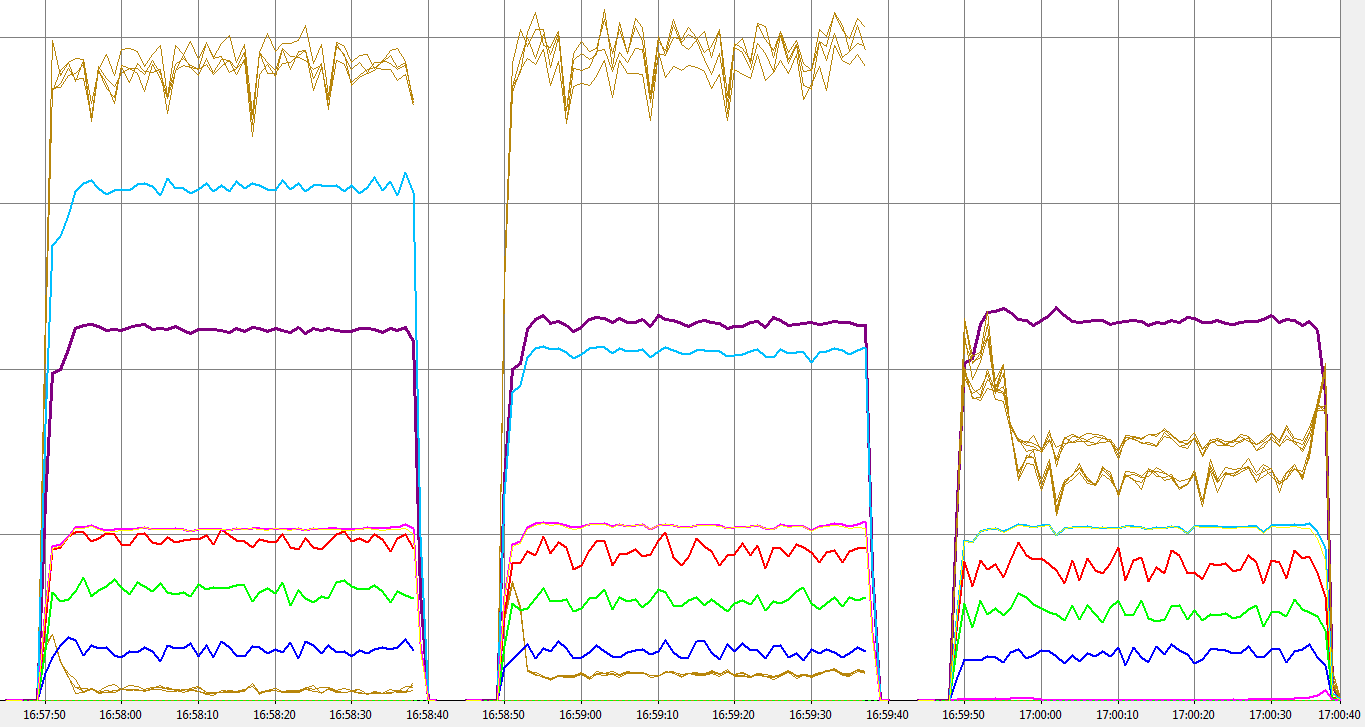
6.2 LowCon - NoSkip, Skip, NoMarshal
Throughput is fractionally better but possibly not enough to make the tuning requirements worth the bother in the case of the buffer allocator. However, given that the low contention pattern can be used in allocators where the only lock free data structure available to me doesn’t work, it’s good to know that it’s a viable design alternative.