Java caches in the middle tier
A common way to improve the performance of Java code is to cache objects rather than repeatedly create and destroy them. This is especially true when you’re writing middle tier servers that service client requests and return results objects. Implementing a flexible caching scheme in Java is relatively easy, but there are a few things to watch for.
The problem
Creating objects in the middle tier that live for only the length of a single client request can be inefficient. When those objects are the results from client requests, and when serveral clients may make requests for the same data, it often makes sense to cache the results. Caching in Java can be implemented relatively easily. After all, the simplest cache is just a map which can store objects based on keys. Sometimes this simple solution is good enough, but usually you want more control over the lifetime of the objects that live in the cache.
This article uses a simple CORBA server to demonstrate increasingly complex cache implementations. This server implements the following interface which allows a client to pass a string and receive a String[][] in return. As we go along we’ll improve the caches that it uses and refactor the code as our design evolves.
typedef sequence<string> StringSeq;
typedef sequence<StringSeq> StringSeqSeq;
interface CacheTest
{
StringSeqSeq DoSelect(in string sql);
}
In JCache1.zip we develop the client/server framework and use a HashMap as a simple cache. We simulate a time-intensive operation to fetch data based on the user’s request and store the results of the queries in the cache for later reuse. The following code from CacheTestImple.java does the work:
public String[][] DoSelect(String sql)
{
String[][] results = findInCache(sql);
if (results == null)
{
results = getData(sql);
addToCache(sql, results);
}
return results;
}
private String[][] getData(String sql)
{
System.out.println("getData(\"" + sql + "\")");
// replace this with a call to a database if you want...
pause(5000);
String[][] results = new String[2][2];
results[0][0] = "Timestamp";
results[0][1] = "Sql";
results[1][0] = new Date().toString();
results[1][1] = sql;
return results;
}
Obviously this is a simplified example, but the concept is valid. If data being retrieved by a request takes some time to obtain, and multiple clients are likely to request it, then it makes sense to cache it. What’s more, due to the way that Java often garbage collects, you may find that a server that caches every result actually has a smaller memory footprint than one that doesn’t!
Building the example code
Install Ant, the build system used by JacORB, and type ‘ant’ in the src directory. If you don’t want to install Ant then it’s fairly easy to take the build.xml files and convert them into normal makefiles.
Running the sample
The scripts directory contains a script to run the server and a script to run the client. The client/server pair use the CORBA naming service to find each other. Run up the JacORB name server (you can use the ns.bat file and the supplied orb.properties and jacorb.properties if you want to). Then run up the server and run the client. By passing different strings on the command line you can make the server return different ‘result objects’ when it needs to create a new result object there is a delay, when it doesn’t because it found the results in the cache the server returns quicker.
A performance tweak for the key to the map
Although caching the results in a simple HashMap improves the performance of our server there’s a small performance tweak that’s probably worth making at this stage. Strings aren’t the best choice for keys in a HashMap as they calculate their hash value every time the hashCode() member function is called. A simple CacheKey can wrap a String and cache the hash… In JCache2.zip we add a CacheKey class which does just that.
Improving on a map
A more complicated cache will need to be able to have some control over the entries that it contains. At present our cache will simply grow and grow as new entries are added to it. However, this may be appropriate for some servers and as we’ve decided that the caching strategy required by one server may not be the same as that required by another server, or even by another cache within the same server, we’ll create an interface that all caches can implement. We will then be able to plug new caches in with ease as long as they conform to our interface.
Our cache interface can look something like this, and we’ll move the CacheKey class inside the interface as it’s so closely related. Since the second Cache in Cache.CacheKey is a bit redundant, we’ll lose it.
public interface Cache
{
public Object find(String keyString);
public Object find(Key cacheKey);
public void add(String keyValue, Object obj);
public void add(Key cacheKey, Object obj);
public void remove(String keyValue);
public void remove(Key cacheKey);
public String name();
public int entries();
public int hits();
public int misses();
public void flush();
public class Key implements Comparable
{
public Key()
...
Next we take our original simple HashMap based cache and implement a SimpleCache which operates in the same way as our “forever growing” cache. We then adjust our server implementation class to use our cache interface and we’re done. JCache3.zip hasn’t changed how our server caches its results, but it has made it far easier for us to change it in the future.
A slightly smarter cache
If the server is going to run for long periods of time then a cache that never purges any entries is unlikely to work that well, unless the possible data set that the server can return is very small. A more useful cache might purge entries that haven’t been used for some time so that once a result has been requested subsequent requests that occur within a certain time of each other will work from the cache. If the object isn’t requested for some time, however, it will be purged to make room for other more commonly requested objects.
To achieve this we need to associate a last used timestamp with each cache entry. We then need some way to store the cache entries in descending order of when they were last used - so we can quickly walk through the entries from least recently used to most recently used. We also need a seperate thread to periodically scan the list to see if the least recently use object in the cache has timed out.
In JCache4.zip we implement a second cache that conforms to our Cache interface. TimeLimitedCache contains a HashMap which we use as the cache and a LinkedList which we use to store the cache elements in least recently used order. We add an ObjectRef class to the Cache interface. The ObjectRef links the object that we’re caching with a timestamp and its key. This makes it easy for the entries to be removed when they time out. Finally we have a thread to periodically check the cache for objects that have timed out. The whole thing is controlled by two member variables, scanEveryMillis - how often the cleanup thread looks for timeouts - and entryTimeoutMillis - how long an entry can stay in the cache after the last client touched it. Both of these variables are set to very low values so that we can see the cache in action.
We’ve changed the client too, it now runs automatically. First it populates the server cache with 10 items and then it requests just one item repeatedly to show that a regularly requested item will remain in the cache after items that aren’t being used are removed. The result objects that the server returns have been adjusted so that they are larger and the server run script now runs the Java VM with verbose garbage collection so that we can see the effect of the cache on the server’s memory usage.
Taking out the trash
If you watch the latest server carefully you’ll notice that it doesn’t garbage collect the objects that have been removed from the cache until an arbitrary time after they’ve been removed. Between the time that the objects are removed from the cache and the time that they are garbage collected the objects are still in memory but completely unusable.
This seems like a bit of a waste. In V1.2 of the Java SDK some classes for working with the garbage collector were added. One of the most useful was the SoftReference class. The SoftReference is a class that can refer to another Object, what makes the SoftReference a little special, however, is that if an object is only reachable through “Soft” references then it is eligible for garbage collection. You can access the object that a SoftReference refers to using the get() method. If the referent has been garbage collected then get() will return null. What’s more, a SoftReference can be registered with a ReferenceQueue and at some point after the SoftReference’s referent is garbage collected the SoftReference will be placed in the ReferenceQueue.
What this means is that you can use SoftReferences and ReferenceQueues to develop some fairly smart caches. By deriving our ObjectRef from a SoftReference and having the SoftReference hold a “soft” reference to our cache item and the ObjectRef hold an additional normal (hard) reference to the cache item we can release the normal reference when the object times out in the cache but still access the object right up until the moment that the garbage collector decides to collect it.
When the object in the cache times out, the cache calls releaseObject() on the ObjectRef. This causes the only “hard” reference to the object to be removed. The object is now only reachable by the “soft” reference and is therefore eligible to be garbage collected. The ObjectRef is still stored in the cache. If a request for the object comes in and the object hasn’t yet been garbage collected then the ObjectRef will be located in the cache. The usage time is updated and get() is called to retrieve the object from the SoftReference. If the object still hasn’t been collected then get() returns a reference to it, the hard reference is reattached, the user gets the object from the cache…
If, however, the object has been garbage collected then get() would return null and the cache lookup would have failed. Eventually the ObjectRef will be placed in the ReferenceQueue that it was associated with when it was constructed. By creating another thread we can poll the ReferenceQueue and remove ObjectRefs as they arrive after the object that they referred to has been collected. As we remove the ObjectRef from the queue we ask it to remove itself from the cache and at that point the purged object is no longer reachable via the cache…
It sounds more complicated than it is, go and look at the code…
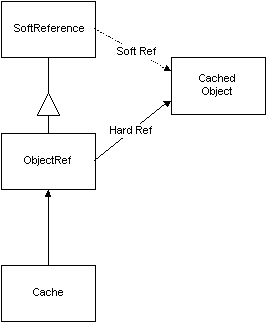
The ObjectRef holds a normal reference to the cached object so it won’t be considered for garbage collection.
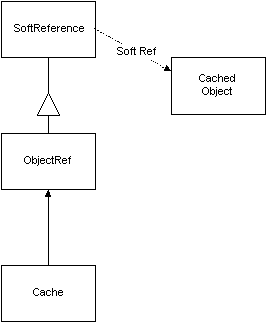
The hard reference is removed as the object is purged from the cache. Now the cached object can only be reached via a soft reference. It will now be considered for garbage collection.
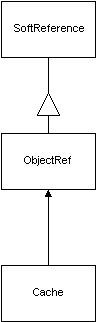
The cached object is garbage collected. The ObjectRef is placed on the ReferenceQueue that was associated with the SoftReference that it derives from. When the ObjectRef is removed from the queue it can be removed from the cache.
Now when we run the client in JCache5.zip you’ll see similar behaviour to before, but you’ll also see each entry garbage collected. When there’s only one entry left it will be allowed to timeout but then accessed before its garbage collected (if my timing code is right :)) and finally allowed to timeout and be garbage collected.
A time to live
Some results objects may only be valid for a certain length of time. Perhaps you have data fed regularly into your database, say, once every hour. It’s OK to cache client requests for up to an hour, but no longer. It doesn’t matter if clients are requesting the same data every minute or two, after an hour you need to query the database again. The data has a maximum time to live and we should be able to create a cache which respects that time to live.
This new kind of cache has quite a lot in common with our TimeLimitedCache. It needs to hold an ObjectRef to the object and store a timestamp and it needs to periodically remove expired entries. If we separate this code out from our existing TimeLimitedCache we can produce a common base class for both the newly named EntryUsageTimeoutCache and our new MaxTimeToLivecache. The common base class will keep the TimeLimitedCache name.
EntryUsageTimeoutCache is the TimeLimitedCache from our previous example refactored so that the new TimeLimitedCache contains code that is common to both types of time limited caches. It provides the periodic cleanup thread and an interface that other time limited caches must adhere to for the cleanup thread to be able to work with them.
The ObjectRefs used by the two caches aren’t actually as similar as they first seem. One needs a timestamp update whenever the object is accessed and the other needs a timestamp that is set only once, when the object is first added to the cache. To add both timestamps to Cache.ObjectRef seems inappropriate. So we’ll move them into classes that derive from Cache.ObjectRef. As it happens, the ObjectRef used by MaxTimeToLiveCache doesnt want the magical object resurrection properties of the SoftReference based Cache.ObjectRef, but the SoftReference stuff is more likely to be used again so we’ll leave that as the standard ObjectRef and just cruft up a new simpler one for the MaxTimeToLiveCache.
In JCache6.zip the server has been changed to use the new cache and the client remains the same. Notice how all of the cache entries are purged, even the one that’s in regular use.
Endless caching strategies
At this point we could continue creating new cache strategies until the cows come home… They’re easy to use because of the common interface and we can write a cache to suit any server’s requirements. The problem is that each time we decide that we need to change how we cache some data we need to modify the program to use the new cache. This is unfortunate and it means that we can’t distribute our application with a “pretty good” cache and also ship the definition of the interface that users can use to write their own better caches if they are so inclined. Luckily, thanks to the wonders of reflection doing this is actually quite easy!
In JCache7.zip we add a CacheManager. The CacheManager manages our caches. It allows users of our caches to always work in terms of just the Cache interface. It’s a factory for caches which can be configured by merging some properties with the system properties and then requesting a cache by name. The property file stores the mapping between the name that’s hard coded in the source code and the cache that actually gets used. The CacheManager is a pluggable factory because it loads the required cache implementations dynamically from their .class files at run-time. It’s user extensible because anyone can write a cache that conforms to our Cache interface, put the .class file in their class path and change the property file to refer to it, all without recompiling the application! That’s pretty cool! The property file contains entries like this:
com.jetbyte.cache7.CacheManager.MYCACHE.CacheClass=com.jetbyte.cache7.EntryUsageTimeoutCache
Where “MYCACHE” is the name of the cache passed to the CacheManager’s getInstance() method. Usually you’d use the name of the object that contains the cache, such as com.jetbyte7.CacheTestImpl in the example. If the object has a need for more than one cache then it can append something to the end of its class name. If the object wishes to share a cache with another object, it can, as long as the two objects agree to call the cache by the same name. Run the new server and experiment by uncommenting each of the config lines in server.properties and restarting the server.
No caches
Since we can now easily change the type of cache used, it would be nice to be able to turn off caching completely as conveniently. In JCache8.zip we implement a NullCache. The object conforms to the Cache interface standard but simply doesn’t bother to cache any of the objects that are given to it. Now you can change the property file to:
com.jetbyte.cache7.CacheManager.MYCACHE.CacheClass=com.jetbyte.cache7.NullCache
and caching is turned off! The best thing about this change is that it’s possible to allow for the special case of “not caching” without having to have any special logic in the application! Not caching is just another kind of caching.
Easy cache configuration
Now that our server is using properties that are merged in with the system properties to configure its cache without the need for recompilation we may as well configure the caches themselves via properties. In JCache9.zip we allow the scanEveryMillis and entryTimeoutMillis variables to be configured on a per named cache basis from properties.
Download
The following source was built using Ant and tested with JacORB 3.21 - the open source Corba Java ORB.
JCache1.zip - a simple HashMap cache
JCache2.zip - a better key
JCache3.zip - use an interface
JCache4.zip - purge the least recently used entries
JCache5.zip - use SoftReferences
JCache6.zip - purge entries after a maximum time
JCache7.zip - use a cache factory
JCache8.zip - turn off caching with a null cache
JCache9.zip - configuration from properties